Every brand suddenly wants the same thing: to get cited by ChatGPT and other LLMs. The problem is that almost all the advice on how to do it is guesswork, because almost nobody shows the data behind their claims. So you end up tightening schema, polishing copy, and hoping, with no way to tell whether any of it moved the needle.
Suganthan Mohanadasan did something better. He reverse-engineered ChatGPT’s source selection from raw network traffic and published what he found. I took his findings and stress-tested them against a real, mature B2B marketing agency, anonymized here as “Agency X,” using Ahrefs’ AI-citation data and a hands-on audit. The kicker: Agency X passed nearly every technical check and ChatGPT still cited it zero times.
This is the claim-by-claim account of what actually decides whether ChatGPT cites you, including two things the original teardown did not cover: an entire content type ChatGPT refuses to search for, and a spam network it cites as though it were a panel of independent analysts. Plus a self-audit you can run on your own site today.
Key Takeaways
- ChatGPT is not a search engine and does not pick sources the way Google does. Optimizing for one does not get you the other.
- Agency X had clean, parseable HTML and a strong backlink profile, and still earned 0 ChatGPT citations.
- Google’s own AI surfaces cited the same site 5 to 6 pages’ worth, which proves this was not a content-quality problem.
- The real bottleneck was the source ecosystem: Agency X had no presence on Reddit, forums, or the other source types ChatGPT pulls from most.
- Some content is uncitable by default: every instructional blog query I tested was answered from ChatGPT’s memory with no web search, so that content cannot be cited no matter how good it is.
- The pipeline that does fire is being gamed: exact-match-domain spam networks with zero Google footprint are cited by ChatGPT as independent authorities.
- You can audit your own ChatGPT exposure in an afternoon. The instructions are at the end.
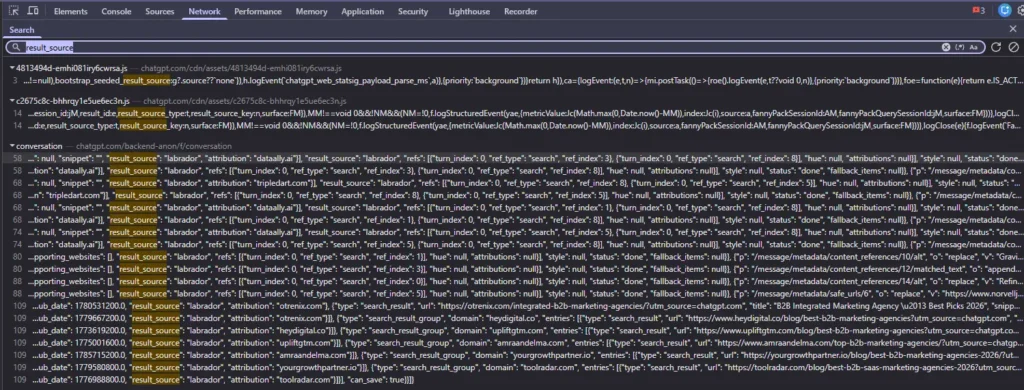
result_source field, read straight from ChatGPT’s network stream. Every cited agency listicle here is tagged labrador, ChatGPT’s licensed and structured quality tier.The Setup: What I Tested and How
Before the findings, here is the hypothesis source, the test subject, and the data lens, so you can judge the results for yourself rather than take them on faith.
The hypotheses, from Suganthan’s teardown
Suganthan analyzed about 1,240 source records captured from ChatGPT’s own network traffic, and the core finding is that ChatGPT does not rank sources the way a search engine does. Instead it pulls from distinct pipelines, and those pipelines have undocumented internal names, visible in a hidden result_source field that ChatGPT attaches to every search result and never shows users.
I believe Mark Williams-Cook was the first to log values for: serp for the open-web baseline, labrador for an allowlist of established publishers such as Reuters, the Guardian, and Wikipedia, bright for what looks like commercially scraped structured data, and then Suganthan found the fourth value, which is oxylabs for a second scraper.
That structure produces a handful of testable claims. Plain, parseable HTML matters because the model cannot cite what it cannot read. You cannot self-cite, so third-party validation decides what gets attributed to you. Reddit punches far above its weight as a citation source. And the throughline for all of it: ChatGPT is not Google, so the playbook is different.
There is one more field worth knowing before any of that fires. A companion value, turn_use_case, classifies your query first and decides which pipelines run at all. Instructional “how-to” queries can be answered straight from training data with no web search performed, which means some content never reaches a citation pipeline no matter how good it is. Hold that thought, because it changes the audit at the end.
This post builds on their work, it does not replace it. Theirs was the network-traffic teardown. Mine is the field test.
The test subject and the data lens
Agency X is a real, mature B2B digital marketing agency that I anonymized for this writeup. It has a strong domain, years of published content, and a full set of service pages, so this is not a thin startup site with nothing for an AI to grab onto. The lens had three parts: Ahrefs AI-citation data for the baseline, meaning its count of citations across AI platforms plus its referring-domain profile; a manual fetch of representative pages to read what an AI parser actually sees; and a set of live ChatGPT queries where I read the same hidden result_source and turn_use_case fields straight from the network stream, the way Suganthan and Mark did.
Caveat
Two honest caveats: this is one site in one vertical, so treat it as directional, not universal. And the live queries ran on logged-out ChatGPT in June 2026, which may search more readily than a logged-in session. The patterns were consistent, but conditions were not identical to the original research.
Finding 1: It Got Cited Zero Times by ChatGPT (But Not by Google)
The headline result is blunt. On the metric everyone cares about, Agency X scored a zero, but only on ChatGPT.
The citation scoreboard
Across AI platforms, Agency X earned 0 ChatGPT citations and 0 distinct cited pages, while Google AI Overviews cited it 13 times across 5 pages and Google AI Mode cited it 9 times across 6 pages. Grok cited it twice. Gemini, Perplexity, and Copilot, like ChatGPT, cited it zero times. The spread is the point. This is not a site that AI systems uniformly ignore. Google’s AI reads it, values it, and cites it. ChatGPT specifically does not. That single contrast rules out the easy explanation that the site is simply low quality, and it forces a harder question about what ChatGPT is doing differently.
| AI platform | Citations | Distinct pages cited |
|---|---|---|
| ChatGPT | 0 | 0 |
| Google AI Overviews | 13 | 5 |
| Google AI Mode | 9 | 6 |
| Grok | 2 | 2 |
| Gemini | 0 | 0 |
| Perplexity | 0 | 0 |
| Copilot | 0 | 0 |
Why “Google cites it but ChatGPT doesn’t” is the whole story
That gap is the thesis of this entire post. Google’s AI leans on Google’s index and the quality signals Google has spent two decades refining, including how it now decides whether to reward or penalize AI-generated content, so a site that earns classic SEO trust gets surfaced in AI Overviews. ChatGPT leans on its own retrieval pipelines and a specific set of third-party and licensed sources. A site can be a first-class citizen in one system and effectively invisible in the other, at the same moment, with no changes to the site itself. Treat them as two different machines with two different appetites.
Finding 2: It Wasn’t a Technical Problem (The Usual Suspect)
The first thing every SEO blames is the tech. So I tested that first, and ruled it out.
The pages render clean, parseable HTML
Suganthan’s number-one cause of non-citation is data trapped behind JavaScript or locked inside images, because ChatGPT cannot cite text it cannot parse. So I fetched representative pages from Agency X, a service page, a blog post, and a case study, and inspected the raw HTML that a parser receives before any script runs. The text was all there, rendered server-side, with no JavaScript gating and no skeleton-loading placeholders. The two pages Google AI Overviews does cite both fit the profile of citable content: concrete declarative claims, specific numbers, and a named-expert quote. Parseability is genuinely necessary. It just was not the thing holding Agency X back, because the site already had it.
Key insight
Agency X passed every technical check and still got cited zero times. If your AEO plan stops at clean HTML and schema, you are optimizing the part that was already fine.
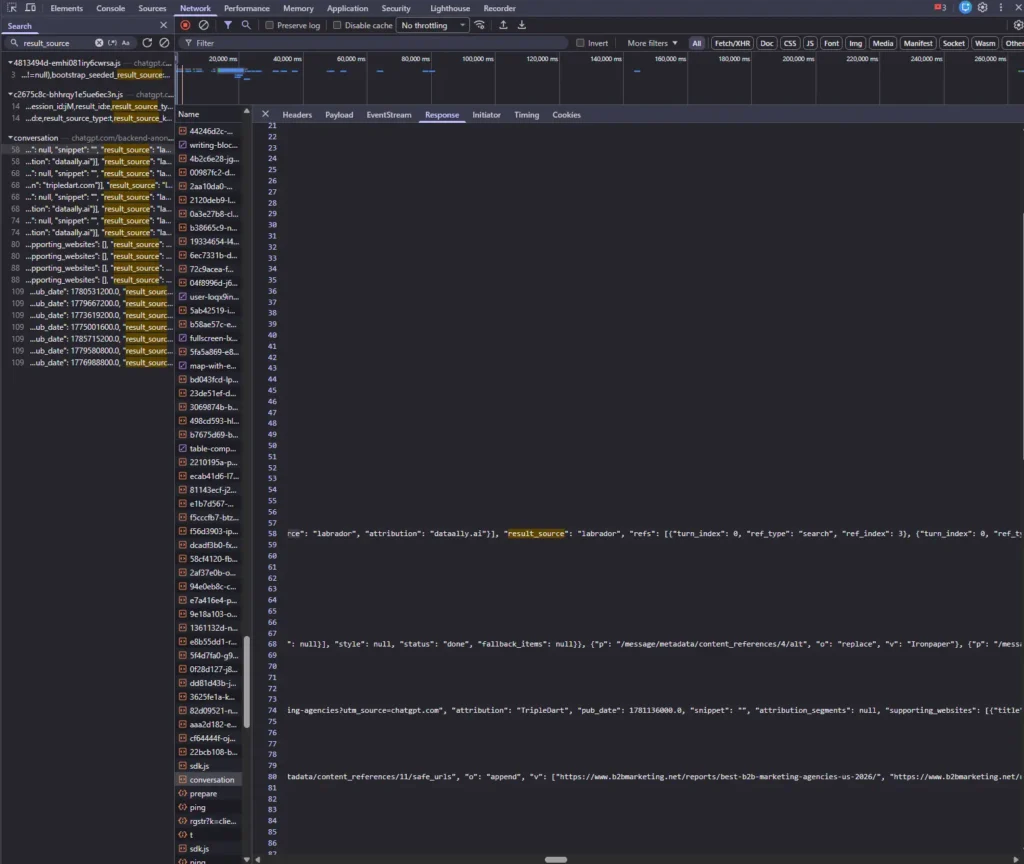
labrador. Agency X appears nowhere.Finding 3: The Real Bottleneck Was the Source Ecosystem
Here is the counterintuitive core of the teardown. The problem was not on the site at all. It was everywhere the site was not.
Strong backlinks, but the wrong kind for ChatGPT
Agency X has serious third-party validation, just not the type ChatGPT draws from. I reviewed more than 250 referring domains. The profile is exactly what you would want for a successful agency: Clutch with 295 links, DesignRush with 315, The Manifest with 183, plus GoodFirms, Expertise.com, the Better Business Bureau, Crunchbase, and earned mentions on Forbes, Inc, and Harvard Business Review. That is a healthy, hard-won link profile. But look at what those sources are. They are agency directories and business press, the referees that win classic search rankings and human buyers comparing vendors. Those directories are not typically inside ChatGPT’s source pipelines. Agency X optimized diligently for the wrong referee.
| Source type | Example domains | Helps classic SEO? | In ChatGPT’s pipeline? |
|---|---|---|---|
| Agency directories | Clutch, DesignRush, The Manifest | Yes | No |
| Mainstream press | Forbes, Inc, HBR | Yes | Sometimes |
| Reddit and forums | (none present) | Indirect | Yes |
| Wikipedia | (none present) | Indirect | Yes |
The smoking gun: zero Reddit, zero Quora
Across all 250-plus referring domains, Agency X had zero presence on Reddit and zero on Quora. Hold that next to Ahref’s finding that Reddit was his most-cited domain, picked up 11 times from 278 fetches, while YouTube was fetched 201 times and cited not once. The site with zero ChatGPT citations also had zero footprint on the exact source type ChatGPT cites most. I want to be careful with the inference: this is strong correlation, not proven causation, and I say so plainly in the limitations. But of every lever on the board, this is the one I would pull first, because it is both the largest gap and the most actionable.
The smoking gun
Agency X had 250+ referring domains, and not one was Reddit or Quora. The single source ChatGPT cites most was the one source it had none of.
Watching it happen: the live commercial-query test
I did not stop at the static backlink profile. I ran Agency X’s highest-value commercial queries through ChatGPT live and read the hidden result_source field on every citation. For “best B2B marketing agency,” “best paid search agency,” “top B2B ecommerce consultants,” and “best B2B SEO agency,” ChatGPT searched and pulled its citations exclusively from the labrador pipeline, the licensed-and-structured quality tier, and in every case it was populated by third-party “best agencies” listicles. Agency X appeared in none of them. That is Finding 3 in motion. The citations exist and they are winnable, but they all route through third-party lists Agency X is not on, which is why publishing more of its own pages would do nothing.
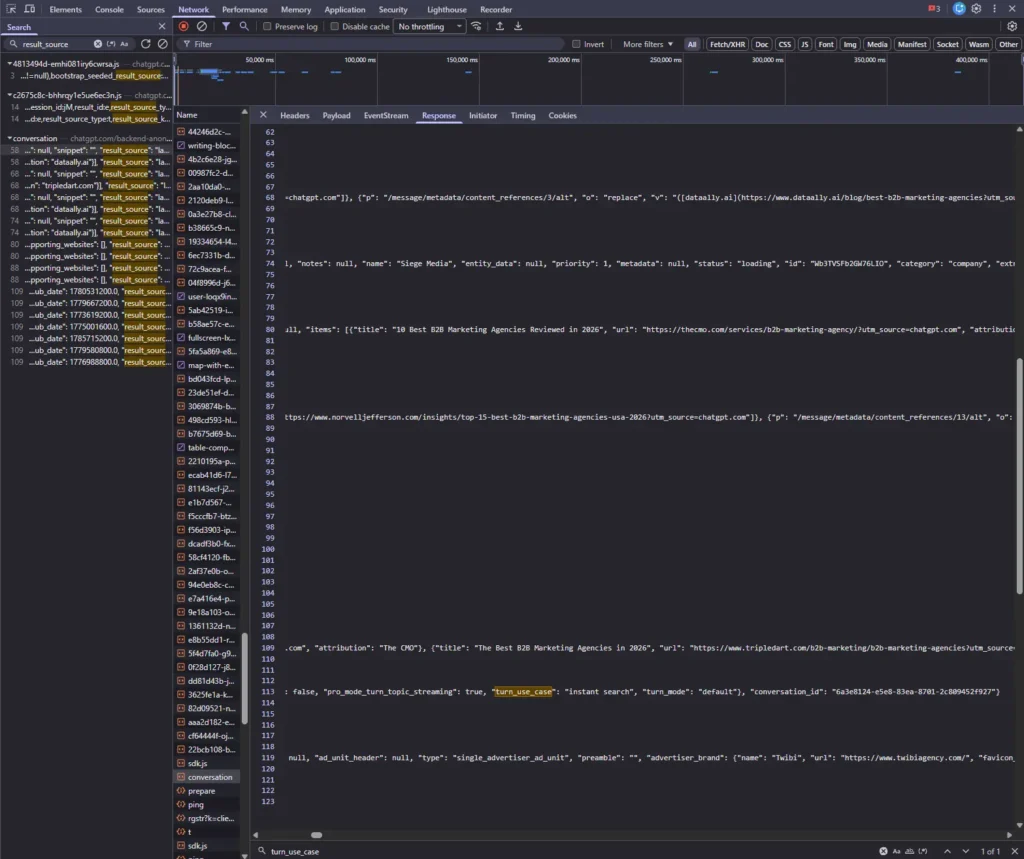
turn_use_case field decides everything before a search runs. Here it reads “instant search,” so the pipelines fired. On instructional queries it reads “text” and no search happens at all. Note the paid single_advertiser_ad_unit riding along.Finding 4: Half the Queries Never Triggered a Search at All
There is a gate before the source pipeline ever opens, and it disqualifies more content than any technical problem could.
The blog targets queries ChatGPT answers from memory
I took the exact topics Agency X’s blog ranks for in Google, the how-to and explainer posts, and ran them through ChatGPT while watching the turn_use_case field that classifies a query before any search runs. Every one came back as text: ChatGPT answered from training data and never ran a web search.
Promoting TikTok shop items, setting up Shopify one-page checkout, questions to ask a PPC agency, addressing the grey market, repurposing blog content, all answered with zero sources fetched.
For that entire category of content, citation is not difficult, it is impossible, because no source pipeline ever fires. Agency X’s blog, built carefully for Google, cannot be cited by ChatGPT no matter how good it gets, because on those queries ChatGPT does not look.
The gate
Five of five instructional blog queries returned a turn_use_case of “text” with no web search. That content cannot be cited by ChatGPT, because ChatGPT never goes looking.
Even some commercial queries skipped the search
The gate is not a clean split between commercial and instructional. “AI search optimization agency,” a buying-intent query I expected to trigger a search, also came back as no-search, answered from memory. So you cannot assume intent maps to behavior. You have to test the specific phrasing your buyers use and watch what ChatGPT actually does, because the classification, not your assumption about intent, decides whether a citation is even on the table.
A note on the ads
One pattern showed up on every query I ran, searched or not: ChatGPT surfaced a single paid advertiser placement. Even the instructional answers that fetched no sources still carried an ad. ChatGPT will sell a placement against your buyer’s question whether or not it cites a single organic source, which means visibility inside these answers may increasingly be a paid motion, not only an earned one.
Finding 5: The Pipeline That Does Fire Is Already Being Gamed
When a search does run, the sources it trusts are not always what they claim to be.
Exact-match-domain networks are manufacturing the listicles
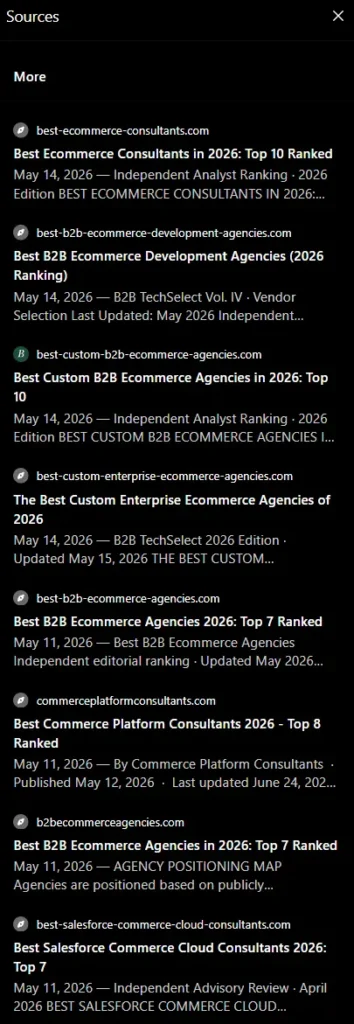
Looking at who actually won the labrador citations, a pattern jumped out. For “top B2B ecommerce consultants,” every cited source was a near-identical “best agencies” listicle on an exact-match domain: best-ecommerce-consultants.com, best-b2b-ecommerce-agencies.com, best-custom-b2b-ecommerce-agencies.com, and several more. They share a server, a publisher banner that describes itself as an independent research publication, the same analyst byline, and the same “100-point methodology, no vendor paid for inclusion” boilerplate. The agency lists differ slightly from page to page. The machinery is identical.
The data confirmed what the eye suspected. Every one of these domains carries a Domain Rating of essentially zero and pulls zero organic traffic from Google, yet each shows between 130 and 240 referring domains, the signature of a manufactured link profile. Google ranks them for nothing. ChatGPT cites them as authorities. They even resolve to the same server address, which is about as close to a fingerprint as this kind of analysis gets.
| Domain | Domain Rating | Organic traffic/mo | Referring domains | Server IP |
|---|---|---|---|---|
| best-ecommerce-consultants.com | 0 | 0 | 213 | 178.128.150.115 |
| best-b2b-ecommerce-development-agencies.com | 0 | 0 | 211 | 178.128.150.115 |
| best-custom-b2b-ecommerce-agencies.com | 0 | 0 | 214 | 178.128.150.115 |
| best-b2b-ecommerce-agencies.com | 0 | 0 | 236 | 178.128.150.115 |
| b2becommerceagencies.com | 2.8 | 0 | 205 | 178.128.150.115 |
| best-salesforce-commerce-cloud-consultants.com | 0 | 0 | 130 | 178.128.150.115 |
Why this should worry you
This is the uncomfortable flip side of “you cannot self-cite.” You cannot cite yourself, but a coordinated operator can spin up a dozen fake “independent” rankings, seat its preferred agencies at the top, and feed ChatGPT’s commercial-query pipeline while Google ignores the whole network.
The defenses Google spent two decades building, link-spam detection and exact-match-domain demotion, are not visibly operating in this pipeline yet. So when you audit who ChatGPT cites for your buyers’ queries, check whether those sources are real. Some of the “authorities” deciding your category may be one operator on one server.
Heads up
Six exact-match domains, one server, Domain Rating zero, zero Google traffic, and ChatGPT cites them as independent analysts. The link spam Google learned to filter is thriving in a pipeline that has not learned to yet.
The Scorecard: What Held Up and What Didn’t
Now tie the whole test together in one honest view, including the claims I could not test.
Claim-by-claim results
A case study is only as credible as the things it admits it could not prove, so here is the full scorecard rather than a victory lap. One of Suganthan’s claims I could not test with this lens, and I am marking it as such rather than implying otherwise.
| Suganthan’s claim | Did it hold up on Agency X? |
|---|---|
| Plain parseable HTML matters | Confirmed important, but Agency X already passed, so not the bottleneck here. |
| You cannot self-cite, you need third parties | Strongly confirmed, and the type of third party is what matters. |
| Reddit over-indexes as a citation source | Indirectly confirmed, its total absence lines up with zero ChatGPT citations. |
| One strong page per claim beats many thin pages | Not directly tested. |
| Query classification, text vs web-search | Confirmed live, 5 of 5 instructional blog queries were classified text with no search, making that content structurally uncitable. |
| ChatGPT is not Google, optimize differently | Confirmed, Google AI cited 5 to 6 pages while ChatGPT cited 0 on the same site. |
The pattern that survives the scrutiny: the on-page fundamentals were fine, and the off-site source mix was the deciding variable.
What This Means For You (and a Self-Audit)
Turn the teardown into something you can act on, because this is where AI search optimization actually lives. The reframe first, then the exact audit.
The reframe: stop optimizing for the wrong referee
Getting cited by ChatGPT is less about your page and more about where else you exist on the web. Classic SEO conditioned all of us to chase directory listings, review-site profiles, and press, and those still matter for Google and for human buyers. ChatGPT rewards a different source set, weighted toward community discussion and reference sources.
So treat AI citation as an off-site and authority problem first and an on-page problem second. This is the natural next layer on top of answer engine optimization, the practice of structuring content so AI assistants can use it, and it is the same instinct behind getting your brand into ChatGPT’s training data in the first place.
The shift runs past citations, too: it is worth giving the models a machine-readable identity page to read about your business, and even making your tools discoverable to AI agents, as the next layers of the same work.
But remember the gate from Finding 4. Before any of this matters, ChatGPT decides whether to search at all, and on instructional queries it often does not. So the first question is not “is my content good enough to be cited,” it is “does my content type even reach a pipeline for the queries my buyers actually ask.” If your content lives on topics ChatGPT answers from memory, the fix is not better content, it is choosing battles where a search actually fires. That is why the audit below starts by watching whether ChatGPT searches at all.
How to run this audit on your own site
You can reproduce my entire test on your own domain in an afternoon.
- First, prompt ChatGPT with the questions your buyers actually ask and watch whether it runs a web search at all. If it answers from memory without searching, that query type is classified as instructional and citations are off the table until you change the question framing or the format.
- Second, compare your ChatGPT citation count against your Google AI count, either with an AI-citation tool or by prompting the assistants directly.
- Third, fetch your most important pages and confirm the substance is in the raw HTML, not injected by JavaScript or stranded inside an image.
- Fourth, inventory your referring domains by type, not just count, and look specifically for Reddit, Quora, forum, and Wikipedia presence.
- Fifth, look hard at who ChatGPT cites for your commercial queries and check whether those sources are legitimate, because some will be exact-match-domain spam networks you can confirm in seconds with a free Domain Rating check.
- Sixth, identify the communities where your buyers actually ask questions and set up AI-citation tracking so you have a baseline to measure against. The Reddit and forum work and the tracking are the highest-yield next moves, but only through genuine participation that earns a mention, never spam.
Conclusion
Next Steps
- Pull your own ChatGPT versus Google AI citation counts.
- Test your buyers’ real questions and note which ones trigger a search at all.
- Audit your top pages for raw-HTML parseability.
- Inventory your referring domains by type, not just number, and check who ChatGPT cites for your category.
- Map the forums and subreddits where your buyers actually ask questions and set an AI-citation baseline.
Self-Audit Checklist
- Prompt ChatGPT with your buyers’ real questions and watch whether it searches the web or answers from memory.
- Compare your ChatGPT citation count against your Google AI citation count.
- Fetch your top pages and confirm the text is present in the raw HTML.
- Inventory your referring domains by type, not just by total count.
- Check who ChatGPT cites for your commercial queries and verify those sources are real, not exact-match-domain spam.
- Map the forums and subreddits where your buyers ask real questions.
- Set up AI-citation tracking to establish a baseline before you change anything.
Frequently Asked Questions
How does ChatGPT decide which sources to cite?
ChatGPT does not rank sources the way Google does. It pulls from distinct pipelines, including licensed publishers, commercial scrapers, and the open search results, then cites what it can parse and attribute. Source type and third-party validation carry more weight than classic on-page ranking signals.
Why isn’t my website showing up in ChatGPT?
Usually it is not a quality problem. First check whether ChatGPT even searches for your buyers’ questions, since instructional queries get answered from training data with no citations at all. If it does search, the likely gap is off-site: the site I tested had clean HTML and strong backlinks but no Reddit or forum presence, the source types ChatGPT favors.
How do you get cited by ChatGPT?
Make your content parseable in raw HTML, then earn third-party mentions on the source types ChatGPT actually draws from, especially community sites like Reddit and reference sources. Self-citation does not work. The off-site source mix matters more than any single on-page tweak.
Does ChatGPT use the same ranking signals as Google?
No. In my test, Google AI surfaces cited the site across 5 to 6 pages while ChatGPT cited it zero times, on the same site at the same moment. Google leans on its index and quality signals. ChatGPT leans on its own retrieval pipelines and licensed or third-party sources.
Do backlinks help you get cited in AI search?
The type of backlink matters more than the count. Agency directories and business press helped the site rank in classic search but did little for ChatGPT, which favors community and reference sources. A large link profile of the wrong type produced zero ChatGPT citations.
Does Reddit help with AI citations?
The evidence points strongly to yes. Suganthan’s data showed Reddit was ChatGPT’s highest-yield citation source, and the site I tested had no Reddit presence and no ChatGPT citations. Genuine, helpful participation in relevant communities is one of the most actionable levers available.
How do you track whether ChatGPT cites your site?
Use an AI-citation tracking tool that records citations across platforms, or prompt the assistants directly with your buyers’ real questions and log which sources they cite. Establish that baseline before you make changes, so you can attribute any movement to what you actually did.
Why does ChatGPT cite low-quality or spammy sites?
Because its commercial-query pipeline does not yet filter link spam the way Google does. In my test, ChatGPT cited a cluster of exact-match-domain “best agency” listicles that shared one server, carried a Domain Rating of zero, and earned no Google traffic at all. Always verify that the sources citing your category are legitimate.
