The same scanner that flagged my site for a missing DNS-AID record also flagged it for not serving “Markdown for Agents.” Both times, the recommended fix was a Cloudflare feature. The first one I couldn’t do at all, because my DNS host couldn’t create the record. This one I could, just not the way the scanner wanted.
I’m on shared LiteSpeed hosting, not Cloudflare. So instead of moving my whole site behind their edge for one checkbox, I built the same Accept: text/markdown content negotiation myself, as a small WordPress plugin. It’s live, this post’s own URL serves markdown if you ask for it, and it’s the next entry in the same “what broke” series as the rest of my agent-readiness work. The one thing that nearly broke it is the thing no guide mentions. And this isn’t theoretical: the most popular coding agents, Claude Code and OpenCode among them, already send Accept: text/markdown on their content requests.
Key Takeaways
- “Markdown for Agents” is just HTTP content negotiation on the
Acceptheader, not a new standard. - Agents want markdown for fewer tokens and cleaner structure. Be honest about the number: I measured about 43% content-to-content, not the 80 to 99% you’ll see quoted.
- You don’t need Cloudflare. It’s a small origin build that works on any host, including WordPress on shared hosting.
- The real trap on a cached host: the page cache serves HTML before PHP runs, so your negotiation code never fires. One
.htaccessline fixes it. - It’s the same content, in an agent-native format, on your canonical URL.
What “Markdown for Agents” Actually Is
It sounds like a new spec. It isn’t. It’s a 30-year-old HTTP feature meeting a new kind of client, plus a reason that client cares.
Content negotiation, the HTTP feature agents rediscovered
Content negotiation allows a single URL to return different formats depending on what the client requests. The agent sends Accept: text/markdown in its request; the server responds with Content-Type: text/markdown and the markdown body. A browser sends no such header, so it keeps getting HTML. Same URL, two representations, chosen per request.
This is native HTTP, not something anyone invented for AI: content negotiation is defined in RFC 9110, and text/markdown has been a registered media type since RFC 7763. The only genuinely new part is that a new class of client, coding agents and LLM fetchers, started sending the header. If a server truly can’t produce what the client asked for, the correct answer is 406 Not Acceptable, though in practice you fall back to HTML.
Why agents want markdown (and the honest token number)
HTML is expensive to read. Tags, class names, inline styles, and scripts all consume tokens without adding meaning. Markdown is the same content stripped to structure, so an agent fits more of your site inside its context budget and parses it more reliably.
How much cheaper? You’ll see big numbers. Cloudflare’s own example clocks its blog post at 16,180 tokens as HTML and 3,150 as markdown, an 80% reduction. The often-quoted “500KB of HTML down to 3KB of markdown” counts the entire page shell, scripts and navigation and all. My own measurement is smaller and, I’d argue, more honest: on my DNS-AID post the plugin clocked 5,730 tokens of article HTML against 3,287 of markdown, about 43% fewer. It’s lower because I’m comparing the article to the article, not the article to a full page of chrome. When someone quotes 90-plus percent, they’re usually counting the stuff you’d never feed a model anyway.
But isn’t HTML winning again in 2026?
Fair objection, and worth answering straight. In May 2026, Claude Code’s Thariq Shihipar argued that HTML is overtaking markdown as the default format for what agents produce. (InfoQ) Bigger context windows took the token pressure off, so the savings that made markdown the obvious choice matter less for what an agent writes.
But that’s about output, what the agent produces. This is about fetch, what the agent reads in. Those are different problems. When you’re loading a web page into a model’s context, markdown still costs fewer tokens and gives cleaner structure than rendered HTML. Serving markdown to agents and having agents emit markdown are not the same debate, and the first one didn’t change.
The Cloudflare Way vs. Building It Yourself
There are two ways to make this happen: flip it on at the edge, or build it at your origin. Here’s why I went the second way.
What Cloudflare’s edge feature does (and who’s recommending it)
Cloudflare’s Markdown for Agents converts your HTML to markdown at their edge whenever it sees the Accept: text/markdown header. It’s a genuinely clean feature and for a lot of sites it’s the right call. Two catches for a site like mine. It only works if your site is proxied through Cloudflare, on a paid plan. And the scanner nudging me toward it, isitagentready.com, is itself a Cloudflare property.
That’s not a conspiracy, it’s an incentive worth naming. A Cloudflare tool will tend to have a Cloudflare-shaped fix. The check is still legitimate. You just don’t have to accept its default remedy.
Why I built it at the origin instead
I’m on shared LiteSpeed hosting, and I wasn’t going to migrate my DNS and proxy to satisfy one checkbox, the same conclusion I reached for DNS-AID. Building the negotiation at the origin is host-agnostic, free, and reuses work I’d already done: I reused the HTML-to-markdown converter from my OKF plugin, which already turns every page into clean markdown for my /okf/ bundle.
It’s also the on-brand move. Every agent signal on this site, from exposing agent tools with WebMCP to the entity map, is a small plugin I can read and change, not a vendor toggle I rent.
Building It on WordPress
Three moving parts: detect the request, convert the content, advertise that the markdown exists. None of them is hard. The part that ties them together, and quietly breaks, comes in the next section.
Detect the header and serve markdown
The core is a template_redirect hook that inspects the request’s Accept header. If it contains text/markdown (and isn’t explicitly refused with q=0), the plugin renders the current post as markdown and sends Content-Type: text/markdown instead of letting the theme render HTML. Browsers, which never send that header, fall straight through to the normal page.
One header matters more than it looks: Vary: Accept. It’s how a cache knows this URL has more than one representation, so it doesn’t hand your markdown to a browser or your HTML to an agent. (RFC 9110) The plugin also adds X-Markdown-Tokens and X-Original-Tokens counts, mirroring what Cloudflare returns, so you can see the savings on any request.
Reuse the markdown you already generate
Here’s the part most people miss: you probably already have a markdown version of your content. If you publish an llms.txt or an OKF bundle, something in your stack is already converting HTML to markdown. Don’t build and hand-maintain a second copy.
My OKF plugin already does this conversion for the /okf/ bundle, so the negotiation plugin borrows the same HTML-to-markdown DOM walker (copied in, so the two plugins stay independent) and wraps the result in a little YAML frontmatter, title, description, and canonical URL, followed by the article body. One source of content, two delivery mechanisms.
Advertise that markdown exists
Negotiation is invisible unless something tells agents to try it. So the plugin adds a per-page <link rel="alternate" type="text/markdown" href="…"> to the HTML head, the standard way to say “a markdown version of this page lives here.” Because that link sits in the HTML body, it survives the page cache, which matters on this host where a PHP-set response header often doesn’t. It’s the same instinct as llms.txt and the OKF bundle, pointed at the canonical URL itself instead of a separate file.
The LiteSpeed Gotcha Nobody Warns You About
This is the part I’d have wanted to read before I started. It’s why “just check the Accept header in your app” quietly does nothing in production, and it’s a one-line fix once you see it.
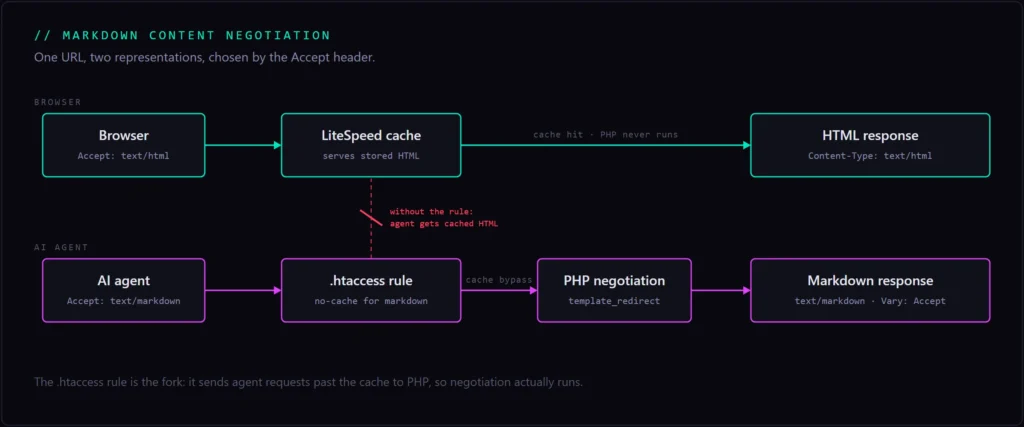
The page cache serves HTML before PHP ever runs
I shipped the plugin, tested it locally, watched it work, deployed it, and the live scan still failed. The reason took me a minute to accept: LiteSpeed, like any full-page cache, serves the cached HTML before WordPress boots PHP, and its cache key doesn’t include the Accept header. So an agent asking for markdown gets handed the cached HTML page, and my negotiation code never runs at all.
This is the trap for anyone bolting request-header logic onto a cached CMS. Every guide says “check the Accept header and return markdown.” That advice assumes your code runs on every request. Behind a page cache, it doesn’t. The cache answers first, in the format it happened to store, and your app never sees the request.
The one-line .htaccess fix
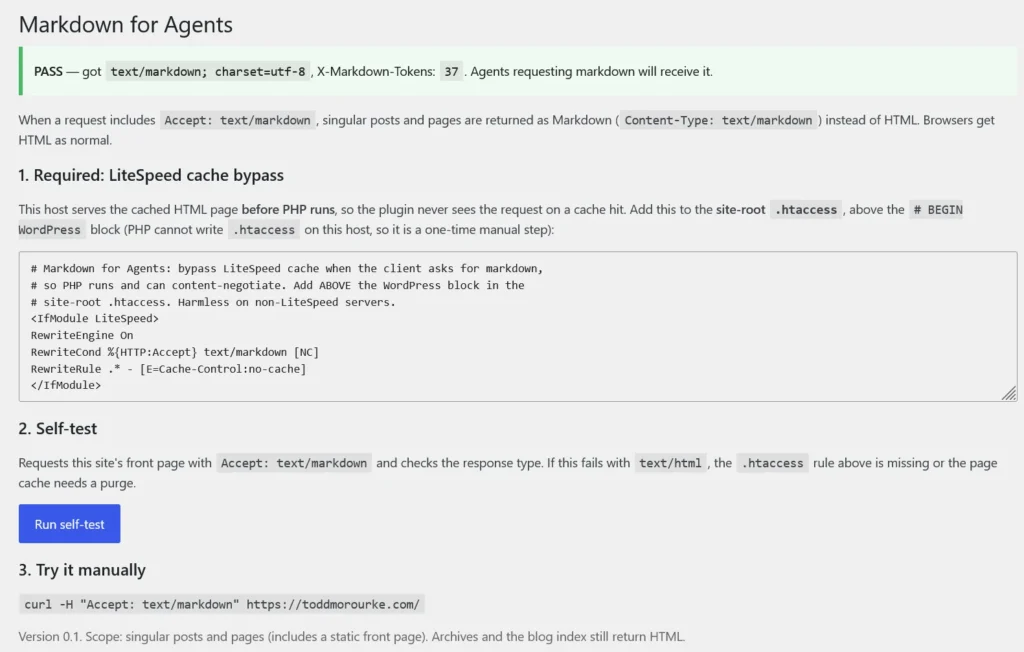
The fix is to bypass the cache for markdown requests only, so PHP actually runs for them. A short rule in the site-root .htaccess does it:
<IfModule LiteSpeed>
RewriteEngine On
RewriteCond %{HTTP:Accept} text/markdown [NC]
RewriteRule .* - [E=Cache-Control:no-cache]
</IfModule>RewriteCond %{HTTP:Accept} text/markdown matches only requests asking for markdown. [E=Cache-Control:no-cache] tells LiteSpeed to skip the cache for them, so the request reaches PHP and gets negotiated. Browsers never match the condition, so they keep hitting the fast cache and nothing about their experience changes. It’s a manual edit, because PHP can’t write .htaccess on this host, and it’s the one path where a PHP-set response header reliably survives: the request is now a genuine cache miss.
Proving It Works
Don’t take my word for it, and don’t take a plugin’s word for it either. Two quick checks tell you whether negotiation is actually live.
The curl test (and the self-test)
Request the same URL twice, once as an agent and once as a browser:
# agent request -> expect Content-Type: text/markdown
curl -sD - -o /dev/null -H "Accept: text/markdown" https://yoursite.com/your-post/ | grep -i content-type
# plain request -> expect Content-Type: text/html
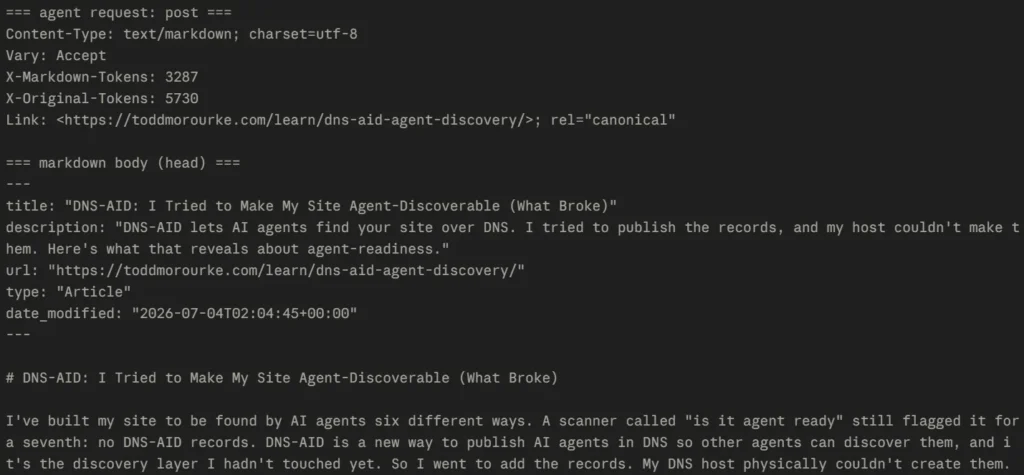
curl -sD - -o /dev/null https://yoursite.com/your-post/ | grep -i content-typeOn my site the first returns text/markdown with an X-Markdown-Tokens header; the second returns text/html, unchanged. The plugin also runs this exact round-trip from an admin button and reports pass or fail, which is how I caught the cache problem in the first place: the button said HTML when it should have said markdown.
What passing actually buys you
Clearing the scanner’s “Markdown for Agents” check is the small win. The real one is the token delta and the parse quality. An agent pulling this post into its context spends roughly 43% fewer tokens on the markdown than on the HTML, and it reads clean structure instead of <div> soup. That’s the AEO payoff: content that’s cheaper to include, easier to quote, and more likely to be cited. And you get it on your own hosting, without renting an edge to do it for you.
Conclusion
Markdown for agents isn’t a new standard to adopt, it’s an old HTTP feature to switch on for a new kind of reader. The interesting work isn’t the negotiation, it’s making it survive a real-world stack. On a cached host that means one small rule most write-ups skip, because most write-ups are running on an edge that hides the problem.
Next Steps
- Curl one of your pages with
Accept: text/markdownand see whether it already returnstext/html(it almost certainly does). - Generate a markdown representation of your content, reusing whatever your
llms.txtor OKF tooling already produces. - Negotiate on the header and send
Vary: Acceptso caches stay correct. - If you’re behind a full-page cache, add the cache-bypass rule and purge.
- Verify with curl, then re-run your agent-readiness scan.
Markdown for Agents Setup Checklist
- Confirm the gap: curl your page with
Accept: text/markdownand check whether it still returnstext/html. - Generate a markdown representation of each page, reusing your existing HTML-to-markdown converter (the one behind your OKF or llms.txt output).
- Negotiate on the
Acceptheader in atemplate_redirecthandler: return the markdown withContent-Type: text/markdownandVary: Accept. - Advertise it with a per-page
<link rel="alternate" type="text/markdown">in the HTML head. - On a full-page cache like LiteSpeed, add the
.htaccessrule that bypasses the cache forAccept: text/markdownrequests, then purge the cache. - Verify with curl (header returns markdown, no header returns HTML) and re-run your agent-readiness scan.
Frequently Asked Questions
What is “Markdown for Agents”?
It’s serving a markdown version of your web pages to AI agents through HTTP content negotiation. When a client sends Accept: text/markdown, the server returns markdown instead of HTML. Browsers, which don’t send that header, keep getting the normal HTML page.
Why do AI agents want markdown instead of HTML?
Fewer tokens and cleaner structure. HTML is full of tags, classes, and scripts that cost tokens without adding meaning. Markdown is the same content stripped to its structure, so it’s cheaper to load into a context window and easier for a model to parse and cite accurately.
Do I need Cloudflare to serve markdown to agents?
No. Cloudflare offers it as an edge feature if your site is proxied through them, but content negotiation is a standard HTTP mechanism you can implement at the origin on any stack, including WordPress on shared hosting. That’s exactly what the plugin behind this post does.
How do you serve markdown from WordPress?
With a small plugin: detect Accept: text/markdown on template_redirect, render the post as markdown, and send it with Content-Type: text/markdown and Vary: Accept. On a cached host you also need an .htaccess rule to bypass the page cache for those requests, or the cache serves HTML before your plugin ever runs.
Does serving markdown to agents hurt my SEO?
No. HTML stays the default for browsers and for Googlebot. Markdown is only returned when a client explicitly asks for it with the Accept header, and Vary: Accept keeps shared caches from mixing the two up. It’s an addition for agents, not a change to what search engines see.
Isn’t HTML replacing markdown for agents in 2026?
That shift is about the format agents output, where bigger context windows have made the token savings matter less. It’s not about what agents fetch. For loading your pages into an agent’s context, markdown still costs fewer tokens and parses more cleanly, so serving it is still worth doing.
