An entity map is a JSON file that tells AI systems what your site knows, the way a sitemap tells crawlers what pages exist. It declares the things you cover, how they connect, and where the proof lives, in a format a model can read without scraping your HTML.
AI retrieval works at the passage level. A model fetches a page, pulls a chunk, and answers, often without ever resolving who published it or how that chunk relates to anything else you’ve written. So your brand gets used in an answer and never named. The same concept, written three different ways across your site, gets treated as three weak signals instead of one strong one. The connections you understand stay buried in prose where a model has to guess at them.
I added an entity map to this site to fix that, both the machine-readable entitymap.json and a human-readable companion page. This post is the spec it follows, the actual code I shipped on WordPress, and the one architecture decision that keeps the two versions from drifting apart.
Key Takeaways
- An entity map (
entitymap.json) is a site-level file that declares your entities, their typed relationships, and source-attributed evidence for AI systems and retrieval pipelines. - It’s not a sitemap and it’s not schema markup. A sitemap lists URLs, schema marks up a single page, an entity map declares what the whole site knows and how it connects.
- It exists because AI retrieval fails at three things: entity disambiguation, publisher attribution, and reading relationships out of prose.
- The build that matters: one data source feeding both the machine file and the human page, so they can’t fall out of sync.
- It’s a real open standard (EntityMap v1.0), not a private invention.
What an entity map actually is
Three things make up an entity map: the analogy that explains it, the parts inside it, and the spec behind it.
The sitemap analogy
sitemap.xml tells crawlers what pages exist. entitymap.json tells AI systems what your site knows. (EntityMap v1.0)
That distinction matters because “what pages exist” stopped being enough. A crawler wants URLs. An answer engine wants meaning: which entities you’re authoritative on, what they are, and how they relate. A list of URLs doesn’t carry any of that. An entity map is the layer that does, sitting next to your sitemap rather than replacing it.
What’s inside it: entities, relations, evidence
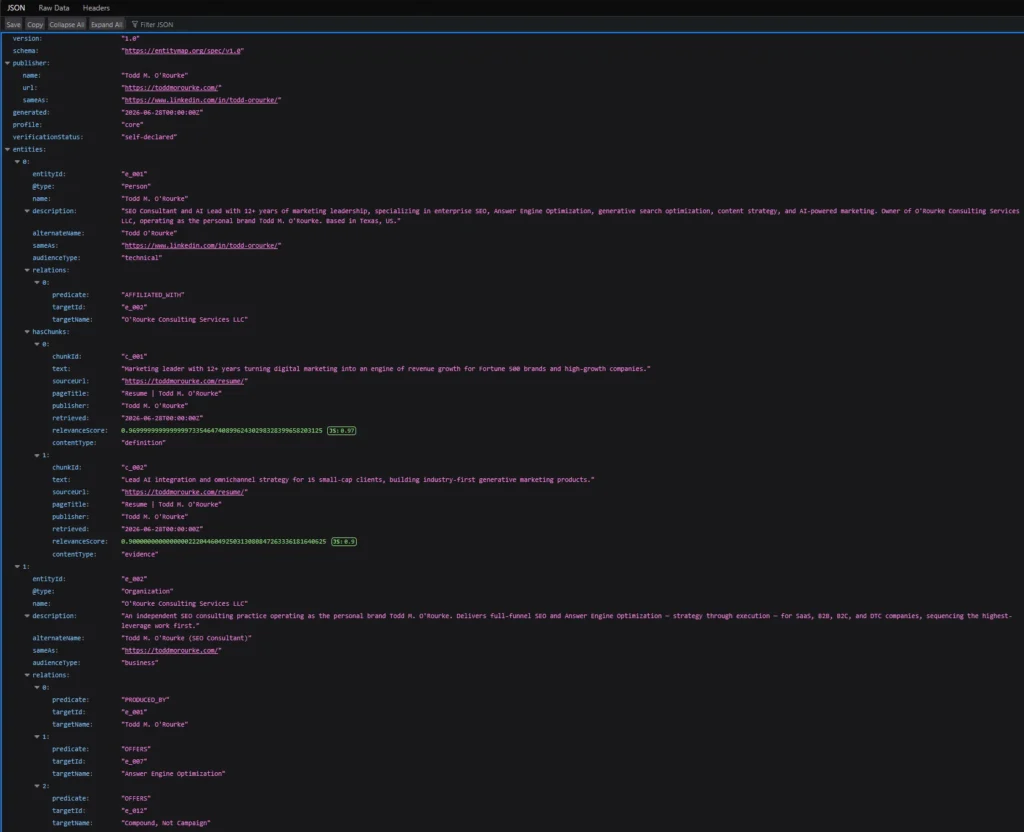
An entity map has three building blocks. Entities are the things you cover: people, products, services, concepts. Relations connect them with a typed predicate and a target. Evidence chunks are short verbatim passages from your pages, each carrying the source URL and publisher attribution.
Here’s one real entity from my map, my ARD Checker tool, related to the concept it implements, with a quote pulled straight from the tool’s page:
{
"entityId": "e_003",
"@type": "SoftwareApplication",
"name": "ARD Checker",
"relations": [
{ "predicate": "RELATES_TO", "targetId": "e_008", "targetName": "Agentic Resource Discovery" }
],
"hasChunks": [
{
"text": "Audit any domain's Agentic Resource Discovery setup...",
"sourceUrl": "https://toddmorourke.com/tools/ard-checker/",
"contentType": "definition"
}
]
}The v1.0 core is small, roughly a dozen required fields across three objects, and the spec has been stable since April 2026. Everything past that is optional enrichment.
It’s an actual spec, not my invention
I didn’t make this format up. It follows the EntityMap v1.0 specification, published openly under CC BY 4.0 by Fred Laurent and Dixon Jones. Other implementations exist, and there’s at least one reference generator that produces conforming files, so this isn’t a single-vendor play.
The independent implementations are the signal I look for before building on something new: people other than the authors are treating it as real. If you want the fuller case for why the standard exists, one of its co-authors laid it out in Search Engine Journal.
Entity map vs sitemap vs schema markup
These three get conflated constantly, so here’s the clean split. A sitemap lists which URLs exist, for crawlers. Schema markup embeds structured facts inside a single page, for Google’s index and some AI. An entity map declares what your whole site knows, how those things connect, and where the evidence is, for AI retrieval and answer engines.
| Artifact | Who reads it | What it declares |
|---|---|---|
sitemap.xml | Crawlers | Which URLs exist |
| Schema markup (JSON-LD) | Search index + some AI | Facts about one page |
entitymap.json | AI retrieval + answer engines | What the whole site knows and how it connects |
The schema comparison is the one people trip on, because both use structured data. The difference is scope and job: schema describes one page to a search index, an entity map describes your site’s whole knowledge graph to a model that’s deciding what you’re authoritative on. They’re complementary, not competing. If you want the deep version of how structured data works across AI systems, I wrote that up separately in my piece on schema markup for AI.
Why an entity map matters for AI search
An entity map fixes three specific failures in how AI reads a site. Each one quietly costs you visibility in AI answers.
One entity, not scattered page signals
The same concept under different surface forms gets read as separate, weaker signals. Call something “AEO” on one page, “answer engine optimization” on another, and “getting cited by AI” on a third, and a model may never connect them. An entity map declares the canonical thing once, with its alternate names attached.
This is entity-based SEO, the idea that search and AI reward distinct, well-defined things over loose keyword strings, carried into the AI-retrieval era. Entity SEO told Google what you’re about. An entity map tells answer engines the same thing, in a file built for them.
Attribution that survives the answer
AI uses your content and drops your name. The URL might show up as a footnote, but the brand never enters the answer text. Every evidence chunk in an entity map carries publisher attribution, so your identity travels with the passage instead of getting stripped at retrieval. If getting cited in AI search is the goal, attribution that survives aggregation is the mechanism.
Relationships declared, not buried in prose
Models infer connections from paragraphs, and inference is lossy. Typed relations make the connection explicit: this tool implements this concept, this person produced this organization. No guessing.
This is the same goal as the rest of the agent-readable stack I’ve been building in public. Agentic Resource Discovery makes a site’s capabilities findable. Open Knowledge Format publishes content as clean files instead of scraped HTML. The entity map is the layer that declares how all of it connects.
How I built mine (with code)
This is the part the explainers skip. The build has four moving parts, and one decision underneath them that does most of the work.
One data source, two outputs
The decision that matters: a single data array is the source of truth, and both the machine entitymap.json and the human page render from it. Hand-maintain two files and they drift, the JSON says one thing, the page says another, and you’ve shipped a contradiction to the exact systems you’re trying to inform.
In WordPress, that source is one PHP function returning the whole document. Both consumers call it:
function tmor_entitymap_doc() {
return array(
'version' => '1.0',
'schema' => 'https://entitymap.org/spec/v1.0',
'publisher' => array( 'name' => "Todd M. O'Rourke", 'url' => home_url( '/' ) ),
'entities' => array(
// ...the entity array, including e_003 above
),
);
}Change an entity once, and the JSON and the page both update. They can’t disagree, because there’s only one of them.
/entitymap.json and the human /entitymap/ page, so they can’t drift; three discovery signals advertise the file.Serving entitymap.json at the root
The spec wants the file at your domain root. In WordPress I serve it by intercepting the request early, sending the right headers, and emitting the JSON:
function tmor_entitymap_serve() {
$path = wp_parse_url( $_SERVER['REQUEST_URI'], PHP_URL_PATH );
if ( '/entitymap.json' !== rtrim( $path, '/' ) ) {
return;
}
header( 'Content-Type: application/json; charset=utf-8' );
header( 'Access-Control-Allow-Origin: *' );
echo wp_json_encode( tmor_entitymap_doc(), JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES );
exit;
}
add_action( 'init', 'tmor_entitymap_serve', 1 );One gotcha cost me a few minutes and it’ll cost you more if you don’t know it: any output before that header() call silently breaks the Content-Type. In my case a UTF-8 BOM at the top of an unrelated plugin file was printing a few invisible bytes first, so headers_sent() was already true, the header got skipped, and the file served as text/html. The JSON looked fine in the body but no parser treated it as JSON. Strip the BOM, make sure nothing prints before headers, and confirm the response is actually application/json.
Making it discoverable
A file at the root that nothing points to is a file nobody fetches. I declare it three ways: a <link> in the page head, an HTTP Link header, and a directive in robots.txt.
add_action( 'wp_head', function () {
printf( '<link rel="entitymap" type="application/json" href="%s">' . "\n",
esc_url( home_url( '/entitymap.json' ) ) );
} );
add_filter( 'robots_txt', function ( $out ) {
return $out . "\nEntitymap: " . home_url( '/entitymap.json' ) . "\n";
} );The spec’s own guidance is robots.txt plus the head plus a visible link. I also reference the map from the identity document my agentic discovery setup already serves, so an agent that finds one finds the other. While I was there, the free tools and the live MCP server show up as entities in the map too, which ties the utilities and the agent endpoint into the same graph.
The human page and its relation graph
The companion /entitymap/ page renders the exact same data, just for people. Each entity becomes a card with its description, its relations as in-page links, and its evidence quotes with sources. Above the cards, an interactive force-directed graph draws the relationships so you can see the shape of what the site knows. The page also emits per-entity JSON-LD, so the entities are first-class structured data, not just styled text. You can look at the live one to see what readers and crawlers get.
How to build and maintain your own
You don’t need my stack to do this. Here’s the practical path, plus the part most people skip.
Start small and grounded
Begin with the entities that actually matter: you, what you offer, and the concepts you genuinely own. The v1.0 core is tiny, so a tight, curated set beats a sprawling one. The spec sets no minimum and only requires sharding once you pass 200 entities, so you’ve got plenty of headroom, but most sites are better off starting with a couple dozen high-value entities than chasing coverage.
Ground every evidence chunk. Each quote must be verbatim from a real page on your site, with its real URL, not paraphrased and not invented. Grounding is the whole credibility argument, an entity map full of approximate quotes is worse than no map.
Publish and declare it
Put the JSON at your domain root, ship a human-readable companion, and declare discovery in robots.txt and the page head with at least one link to it. That’s the minimum a model needs to find and trust the file.
Keep it current
An entity map isn’t a sitemap that regenerates itself. It’s an assertion you’re making, so it goes stale when your facts change and nobody updates it. Update it when entities or facts change, and watch your evidence URLs especially: if you prune or redirect a post that a chunk cites, that evidence now points at a dead page. I review mine on a fixed cadence and re-check every source URL when I do.
Key insight
The most common failure mode is ship-it-once and abandon it. A stale entity map asserting dead source URLs is worse than not having one, because you’re handing AI systems confident claims that no longer check out.
Conclusion
An entity map is the cheapest way I’ve found to tell AI systems what your site is actually about, as connected entities with sourced proof, instead of leaving them to reverse-engineer it from your HTML. The build is straightforward. The discipline of keeping it grounded and current is the real work.
Next Steps
- Look at my entity map and its
entitymap.jsonto see a working example before you build. - List the ten to fifteen entities your site is genuinely authoritative on.
- Draft a minimal
entitymap.jsonfrom the v1.0 spec, with one grounded evidence chunk per entity. - Publish it at your root, declare it in robots.txt and your head, and put a review date on your calendar.
If you want your site legible to AI systems and not just crawled, that’s the AEO and AI search work I do.
Entity Map Checklist
- List the entities your site is actually authoritative on: you, your offerings, the concepts you own.
- Add typed relations between them and one or two verbatim evidence chunks per entity, each with a real source URL.
- Put your data in a single source of truth, then render both
entitymap.jsonand a human companion page from it. - Serve
entitymap.jsonat your domain root with the correctapplication/jsonContent-Type, and confirm nothing prints before the headers. - Declare discovery: a head
<link rel="entitymap">, aLinkheader, and a robots.txtEntitymap:directive. - Validate the file against the EntityMap spec and confirm every evidence URL resolves.
- Re-review on a fixed cadence and repoint evidence URLs whenever you prune or redirect content.
Frequently Asked Questions
What is an entity in SEO?
An entity is a distinct, well-defined thing a search engine or AI can recognize: a person, place, organization, product, or concept. Unlike a keyword, which is just a text string, an entity has a stable meaning, so “Apple” the company and “apple” the fruit are different entities even though the word is identical.
What’s the difference between keywords and entities?
Keywords are the literal words people type. Entities are the real-world things those words refer to. Search and AI moved from matching strings to understanding entities, so optimizing for entities means making sure systems know which distinct thing your content is about, not just which words it contains.
What is an entity map (entitymap)?
An entity map, published as entitymap.json, is a site-level file that declares the entities your site covers, the typed relationships between them, and source-attributed evidence for each. It gives AI systems and retrieval pipelines a structured view of what your site knows, rather than making them infer it from raw HTML.
How is an entity map different from a sitemap?
A sitemap lists which URLs exist so crawlers can find your pages. An entity map declares what your site knows and how those things connect so AI systems can understand it. One is an index of pages, the other is an index of meaning. They serve different consumers and you publish both.
What’s the difference between an entity map and schema markup?
Schema markup embeds structured facts inside a single page for search indexes and some AI. An entity map is a site-level file declaring your whole knowledge graph and its relationships for AI retrieval. Schema describes one page, an entity map describes your site. They complement each other rather than overlap.
What is entity-first SEO?
Entity-first SEO starts from the distinct things you want to be known for, then builds content to cover those entities and their relationships, instead of starting from individual keywords. An entity map is that approach made concrete: it’s your entities and their connections declared in a single file for machines.
Does an entity map help with AI search?
It helps in the ways AI retrieval currently fails: it disambiguates your entities, attaches publisher attribution to evidence so your brand survives into answers, and declares relationships explicitly instead of leaving models to guess. This isn’t a ranking trick. It gives AI systems a cleaner, attributable view of what you know.
Is EntityMap a real standard, and who created it?
Yes. EntityMap is an open specification, version 1.0, published under a Creative Commons license by Fred Laurent and Dixon Jones. It has independent implementations and a reference generator, and it’s been covered in the SEO press as an emerging open standard, so it’s not a single-vendor format.
Where do you publish entitymap.json, and how many entities should it have?
Publish it at your domain root, with a human-readable companion page, and declare it in robots.txt and your page head. For entity count, favor a focused, curated set over a sprawling one. The spec sets no minimum and only requires sharding past 200 entities, so start with the couple dozen things you’re genuinely authoritative on, each with grounded evidence.
